Des ordinateurs « organiques », composés d’ADN capables de traiter les données de notre corps ?
Nous imaginons invariablement que les composants électroniques sont des puces de silicium, grâce auxquelles les ordinateurs sont capables de stocker et traiter des informations sous forme de chiffres binaires (zéros et uns) et représentés par de minuscules charges électriques. Mais cela peut être fait autrement : parmi les solutions de remplacement du silicium, l’ADN pourrait être l’élément organique étant la meilleure alternative.
Les ordinateurs à ADN ont été pour la première exposés en 1994 par Leonard Adleman, qui a codé et résolu le problème du commercial en déplacement, un problème mathématique visant à trouver le trajet le plus efficace et rapide pour un vendeur devant se déplacer d’une ville à l’autre. Ce problème a entièrement été résolu grâce à l’ADN.
L’Acide DésoxyriboNucléique (ADN), permet de stocker de grandes quantités d’informations codées en tant que séquences des molécules, appelées nucleotides, Cytosine (C), Guanine (G), Adénine (A) ou Thymine (T). La complexité et l’impressionnant écart de codes génétiques entre les différentes espèces démontre le nombre d’informations qui peuvent être stockées dans l’ADN codé en utilisant ces molécules C.G.A.T. Cette capacité peut être mise à profit dans l’industrie informatique. Des molécules d’ADN peuvent être utilisées pour traiter l’information selon un procédé de liaison entre les paires d’ADN, l’hybridation.
Depuis qu’Adleman a réalisé cette expérience, beaucoup de circuits à base d’ADN ont été proposés, mettant en oeuvre des méthodes de calcul telles que la logique booléenne et des formules arithmétiques. Appelée « programmation moléculaire », cette façon de programmer est réellement de la biochimie. Les programmes créés sont en réalité des méthodes de sélection de molécules interagissant d’une façon aboutissant à un résultat spécifique à travers le processus de l’ADN auto-assemblé où les collections désordonnées de molécules interagissent spontanément pour former l’agencement souhaité des brins d’ADN.
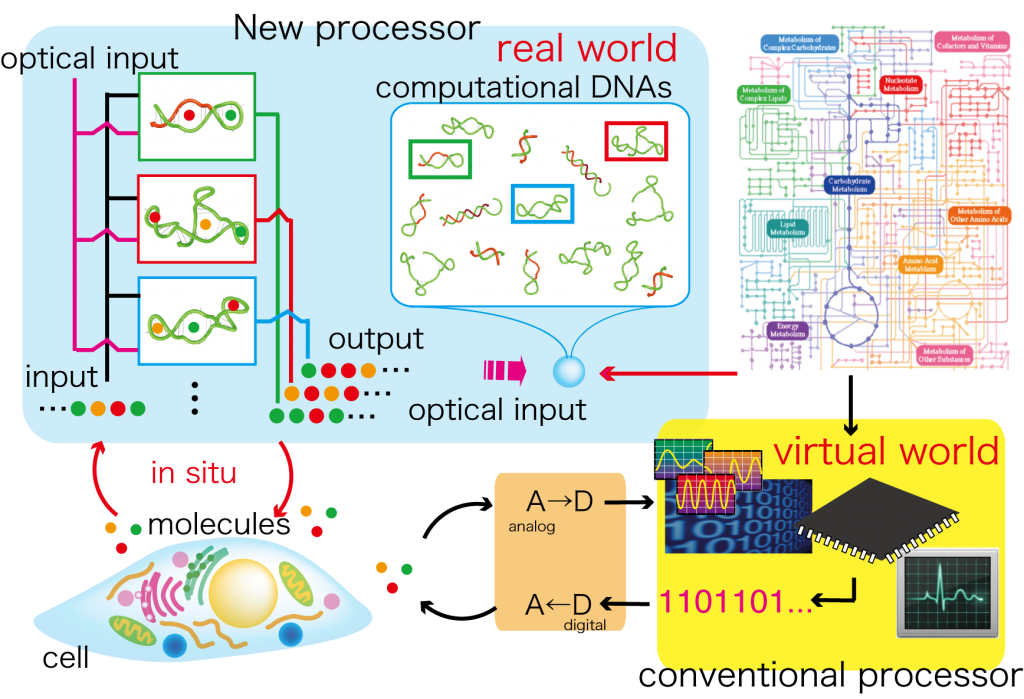
Source image : http://www-lip.ist.osaka-u.ac
Pourquoi l’ADN informatique ?
Les caractéristiques intéressantes des molécules d’ADN sont, entre autre, leur taille (2nm), leur programmabilité et leur capacité de stockage qui est beaucoup élevée que celles de leurs homologues de silicium. L’ADN est également polyvalent, peu coûteux et facile à synthétiser.
Son plus gros inconvénient est sa vitesse : actuellement, il faut plusieurs heures pour calculer la racine carrée d’un nombre à quatre chiffres. Quelque chose qu’un ordinateur classique calculerait en un centième de seconde. Un autre inconvénient serait que les circuits d’ADN sont à usage unique et doivent être recréés de zéro afin de relancer le même calcul.
Son plus gros avantage est qu’il peut interagir avec son environnement biochimique. L’ADN informatique consiste à reconnaître la présence ou l’absence de certaines molécules. Et donc l’un des travaux naturels de l’ADN informatique est d’apporter cette programmation dans le domaine des biocapteurs de l’environnement ou de la délivrance de médicaments et de thérapies à l’intérieur d’organismes vivants.
Quel avenir pour l’ADN informatique ?
Globalement, l’ADN informatique a un énorme potentiel d’avenir. Sa capacité de stockage impressionnante, son faible coût énergétique, sa facilité de fabrication exploitant la puissance de l’auto-assemblage et son affinité avec le monde naturel sont les clés d’entrées à l’informatique à une échelle nanométrique. Depuis sa création, cette technologie a progressé à une vitesse incroyable, étant maintenant capable de diagnostiquer une maladie et de prendre des décisions quant au traitement à y apporter.
Articles susceptibles de vous intéresser sur le même thème :
- Pourquoi la gorge du lézard Jamaïcain brille ?
- La NASA défie les lois de la physique
- Un hologramme palpable
- La geckovescence, quésako ?
- L’homme qui pouvait entendre le WiFi
- Carte souterraine des câbles enfouis dans les océans
- Un hologramme palpable
- Votre emploi peut-il être remplacé par un robot ?